






芯片资讯
热点资讯
- 晶导微 MM1W20AHE 1W20V稳压二极管SOD-123HE的技术和方案应用介绍
- 晶导微 MM1Z30BW 0.5W30V稳压二极管SOD-123W的技术和方案应用介绍
- 晶导微 GBJ2006 20A600V大功率整流桥GBJ的技术和方案应用介绍
- 晶导微 MM3Z15W 0.3W15V稳压二极管SOD-323W的技术和方案应用介绍
- 晶导微 GBJ3510 35A1000V大功率整流桥GBJ的技术和方案应用介绍
- 四维图新旗下世纪高通获“北京市市级企业技术中心”认定
- 晶导微 MMSZ5257BW 0.5W33V稳压二极管SOD-123W的技术和方案应用介绍
- 晶导微 MM3Z33W 0.3W33V稳压二极管SOD-323W的技术和方案应用介绍
- 亿纬锂能发布“麟驹”系列电池
- 晶导微 S9018 NPN三极管SOT
- 发布日期:2024-01-05 13:45 点击次数:135
自2023年以来,AI大模型在全球范围内掀起了有史以来规模最大的人工智能浪潮。国内学术和产业界在过去一年也有了实质性的突破。中文大模型测评基准SuperCLUE在过去一年对国内外大模型的发展趋势和综合效果进行了实时跟踪。
基于此,SuperCLUE团队发布了《中文大模型基准测评2023年度报告》,在AI大模型发展的巨大浪潮中,通过多维度综合性测评,对国内外大模型发展现状进行观察与思考。
国内大模型关键进展012023年大模型关键进展与中文大模型全景图
国内学术和产业界在过去一年也有了实质性的突破。大致可以分为三个阶段,即准备期(ChatGPT发布后国内产学研迅速形成大模型共识)、成长期(国内大模型数量和质量开始逐渐增长)、爆发期(各行各业开源闭源大模型层出不穷,形成百模大战的竞争态势)。
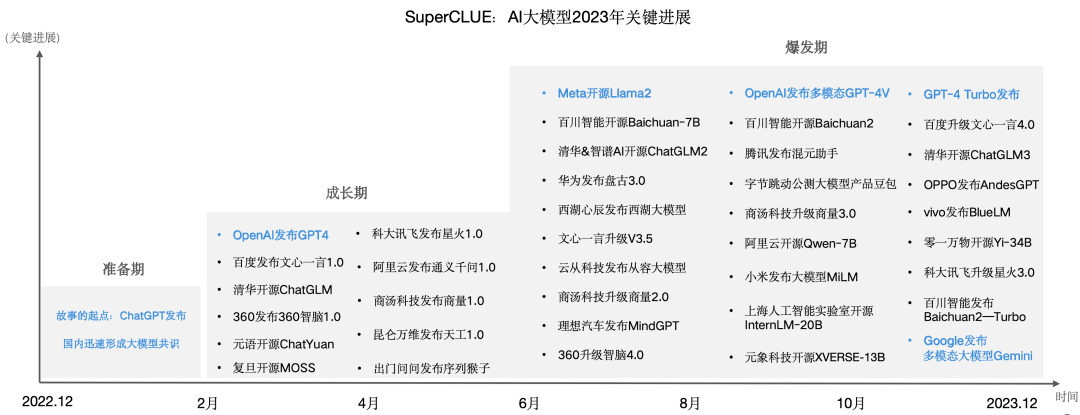
截止目前为止,国内已发布开源、闭源通用大模型及行业大模型已有上百个,SuperCLUE梳理了2023年值得关注的大模型全景图。

022023年国内外大模型发展趋势
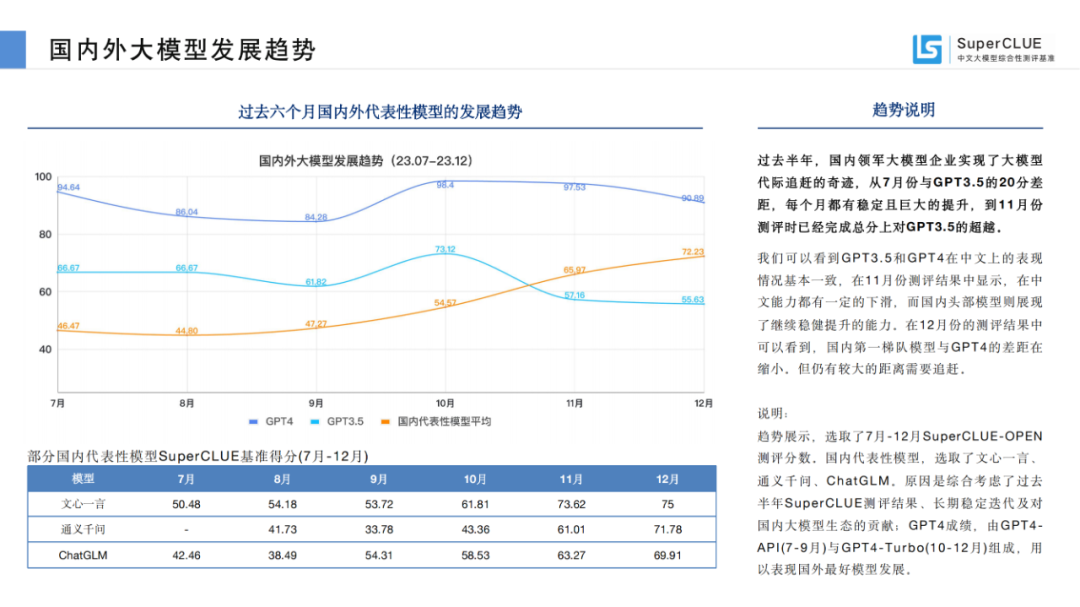
过去半年,国内领军大模型企业实现了大模型代际追赶的奇迹,从7月份与GPT3.5的20分差距,每个月都有稳定且巨大的提升,到11月份测评时已经完成总分上对GPT3.5的超越。
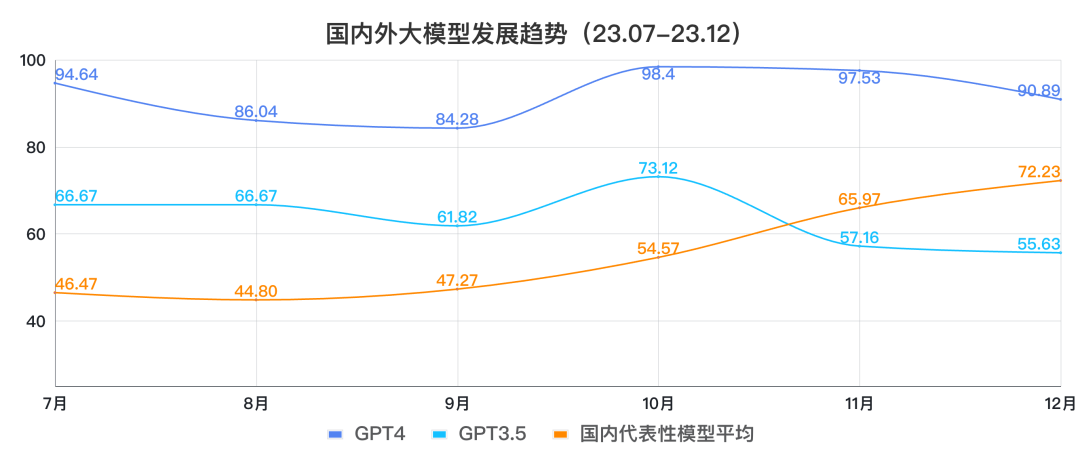
数据来源于SuperCLUE基准得分(7月-12月)
我们可以看到GPT3.5和GPT4在中文上的表现情况基本一致,在11月份测评结果中显示,在中文能力都有一定的下滑,而国内头部模型则展现了继续稳健提升的能力。在12月份的测评结果中可以看到,国内第一梯队模型与GPT4的差距在缩小。但仍有较大的距离需要追赶。

数据来源于SuperCLUE基准得分(7月-12月) 说明:趋势展示,选取了7月-12月SuperCLUE-OPEN测评分数。国内代表性模型,选取了文心一言、通义千问、ChatGLM。原因是综合考虑了过去半年SuperCLUE测评结果、长期稳定迭代及对国内大模型生态的贡献;GPT4成绩,由GPT4-API(7-9月)与GPT4-Turbo(10-12月)组成,用以表现国外最好模型发展。  大模型综合测评结果 01测评模型列表
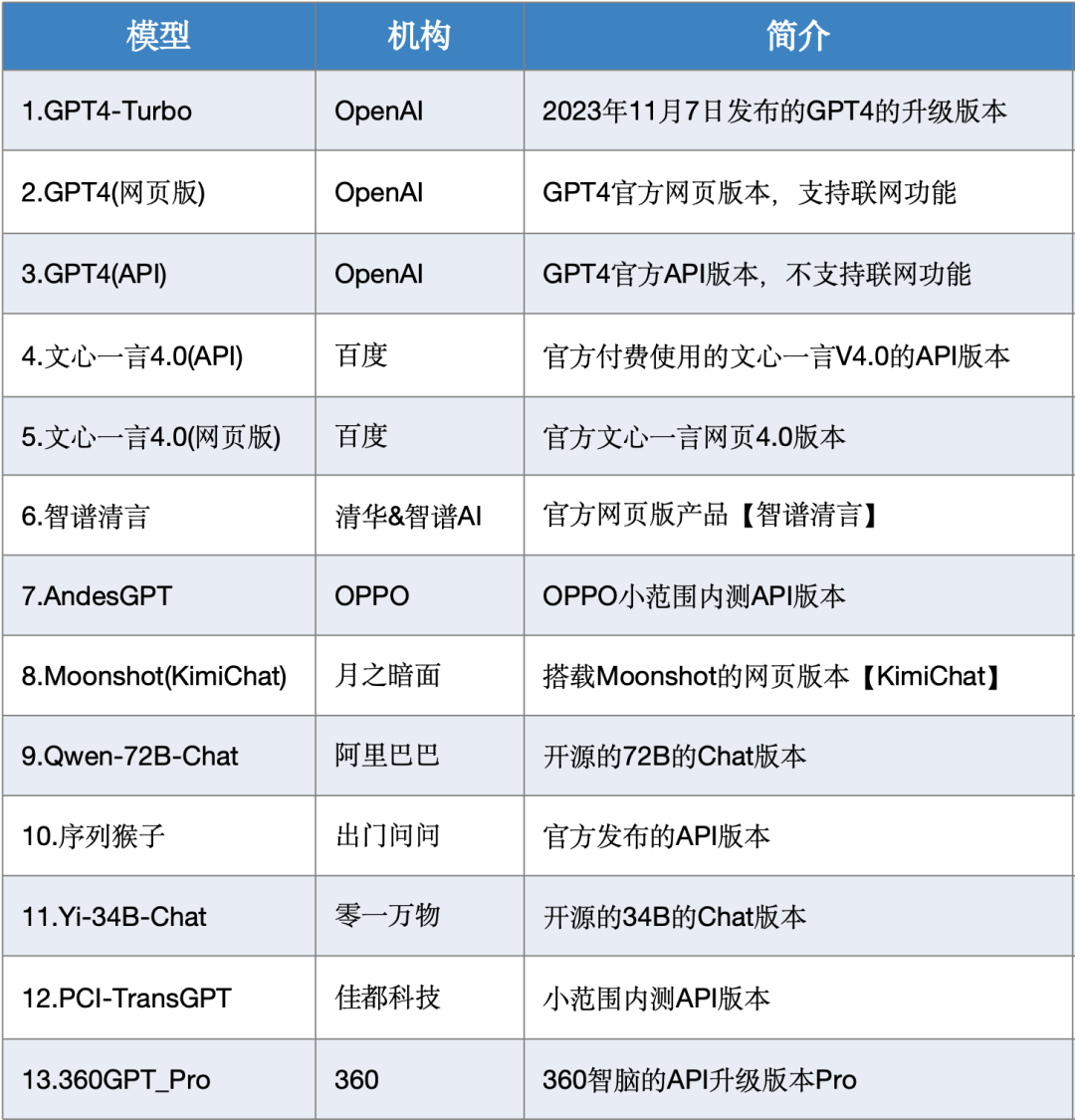
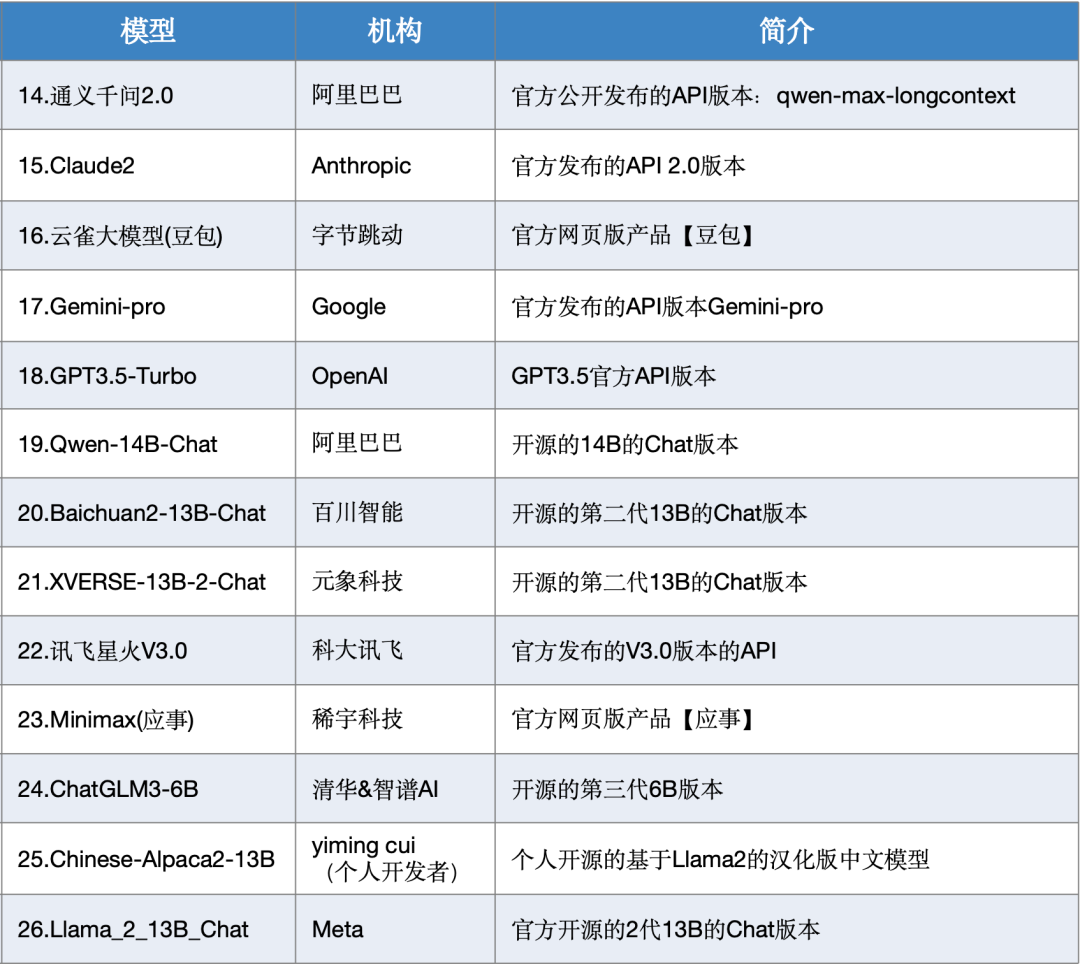
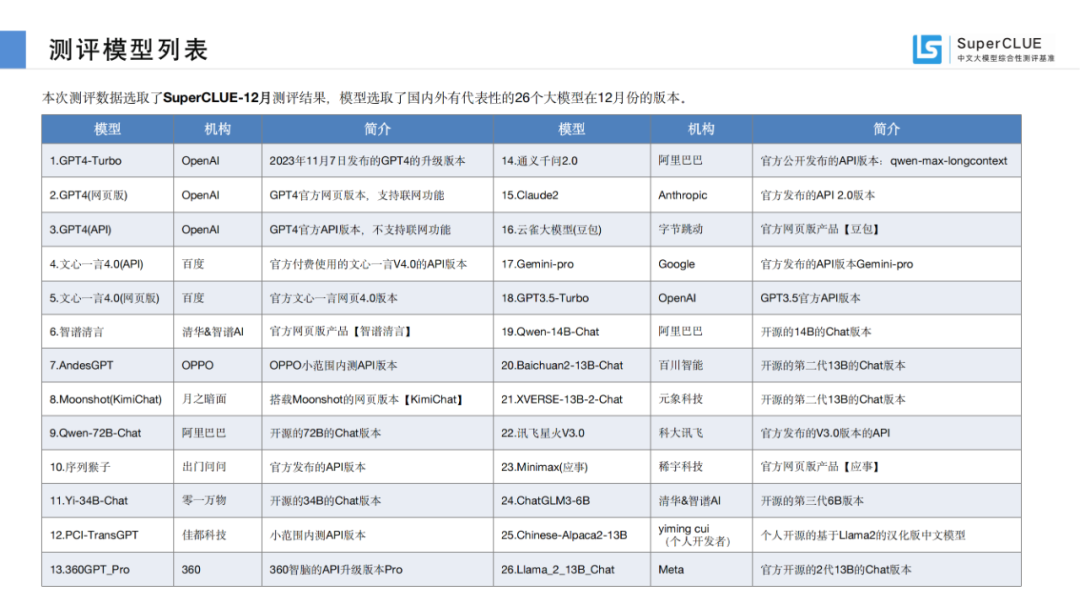
大模型综合测评结果 01测评模型列表
本次测评数据选取了SuperCLUE-12月测评结果,模型选取了国内外有代表性的26个大模型在12月份的版本。
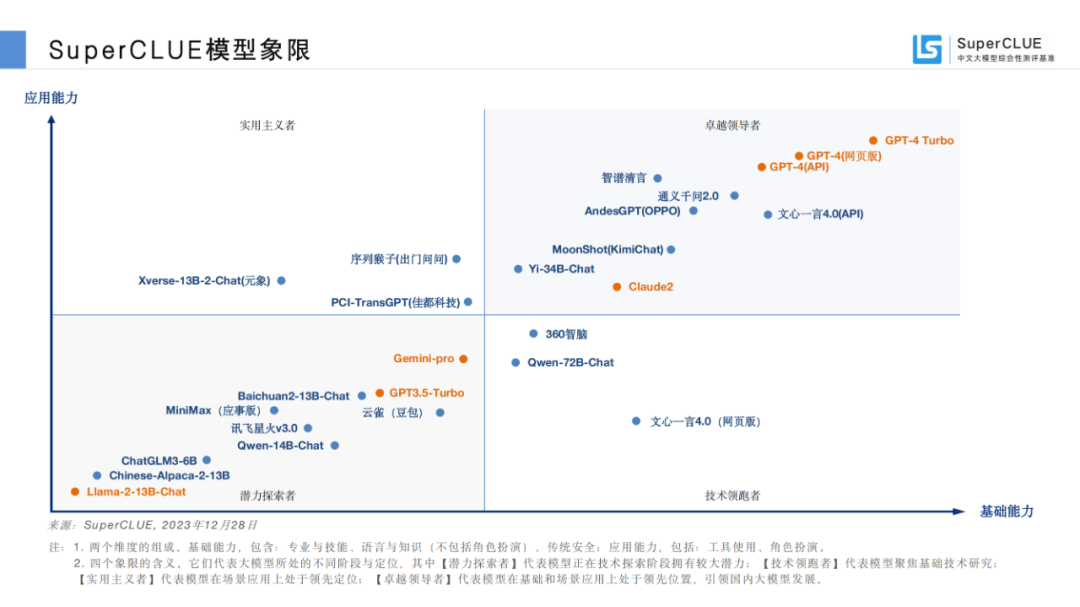
02SuperCLUE模型象限
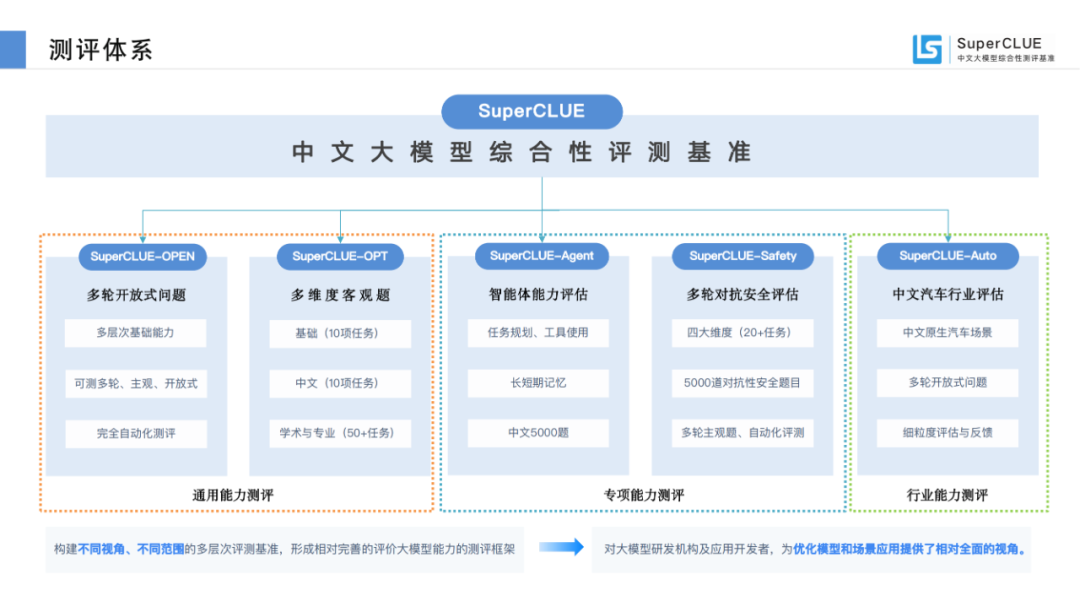
SuperCLUE评测任务可划分为基础能力和应用能力两个维度。
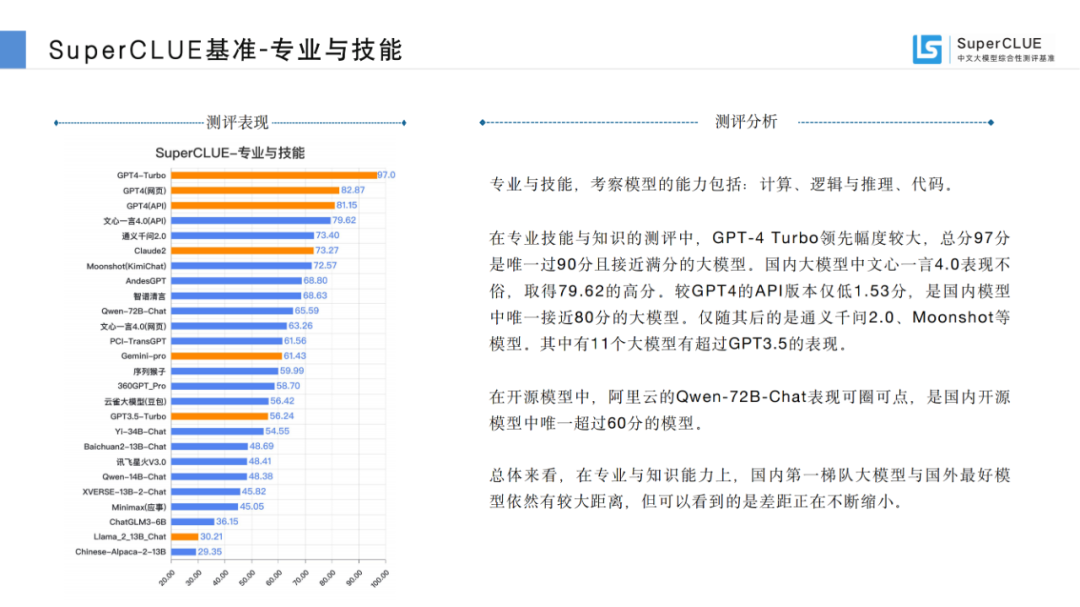
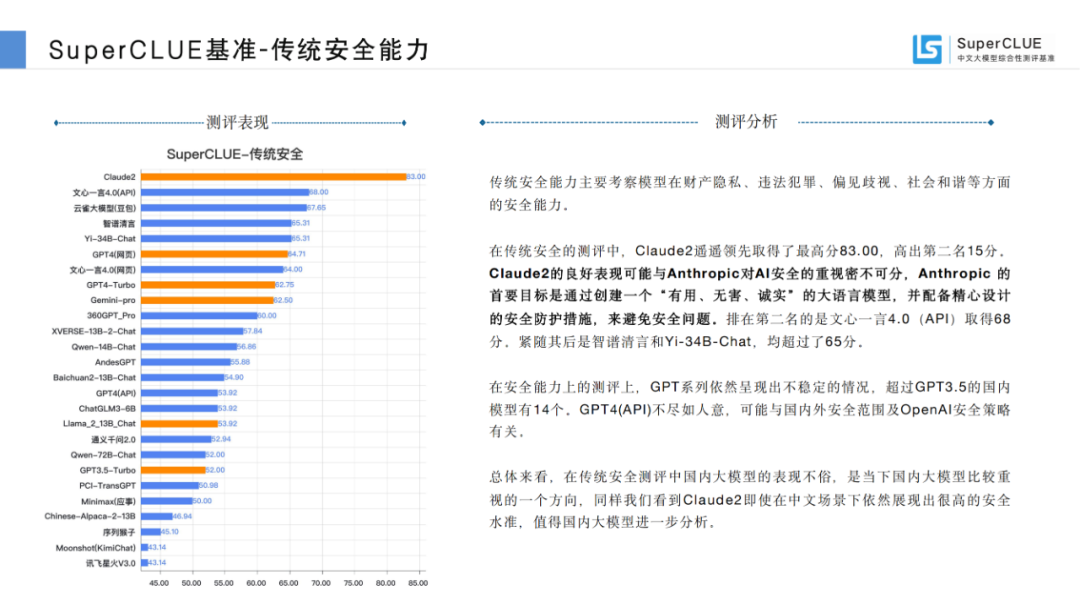
基础能力,包含:专业与技能、语言与知识(不包括角色扮演)、传统安全;
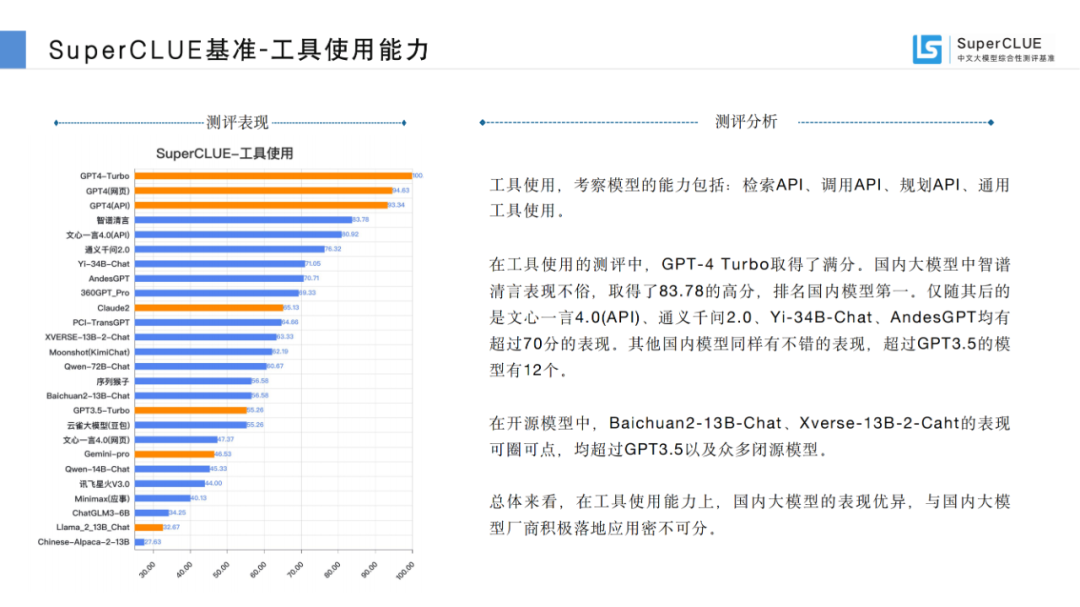
应用能力,包括:工具使用、角色扮演。
基于此,SuperCLUE构建了大模型四个象限,它们代表大模型所处的不同阶段与定位,其中【潜力探索者】代表模型正在技术探索阶段拥有较大潜力;【技术领跑者】代表模型聚焦基础技术研究;【实用主义者】代表模型在场景应用上处于领先定位;【卓越领导者】代表模型在基础和场景应用上处于领先位置,引领国内大模型发展。
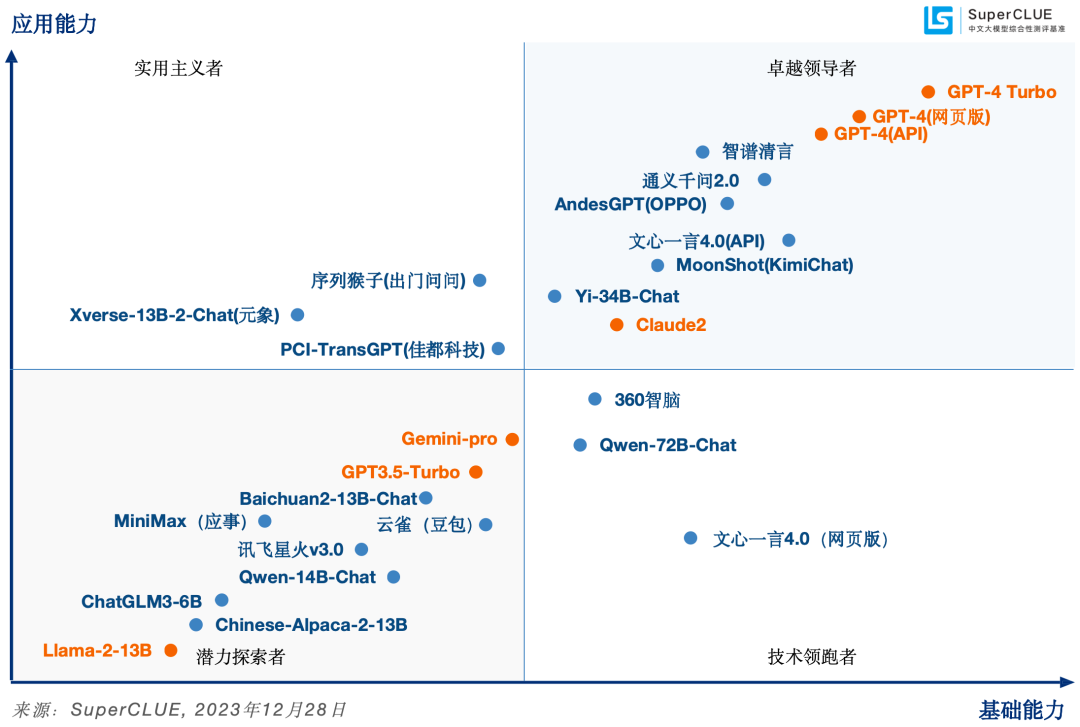
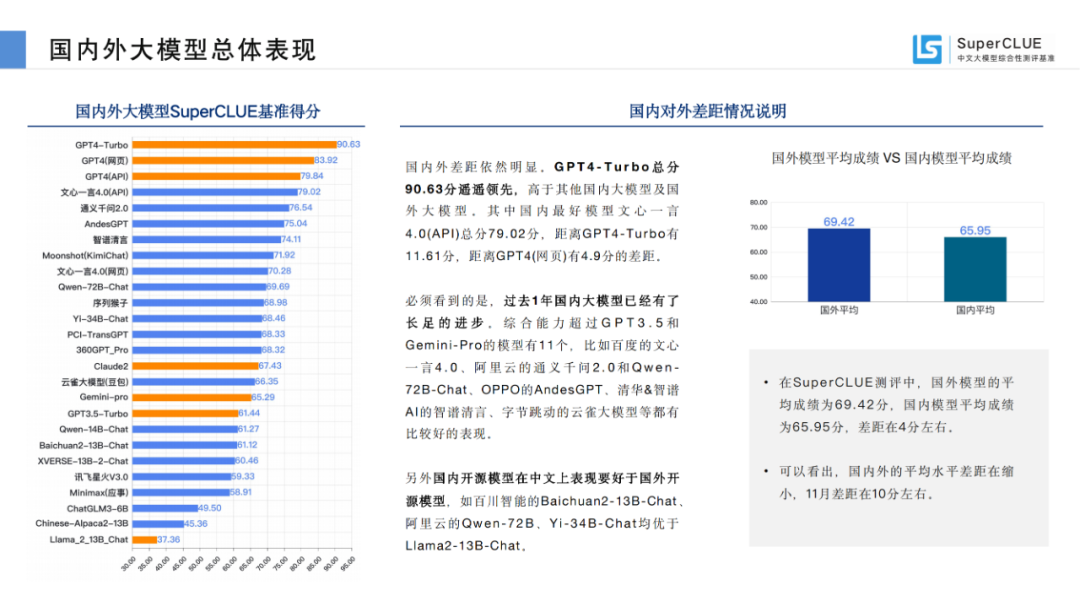
03国内外大模型总体表现
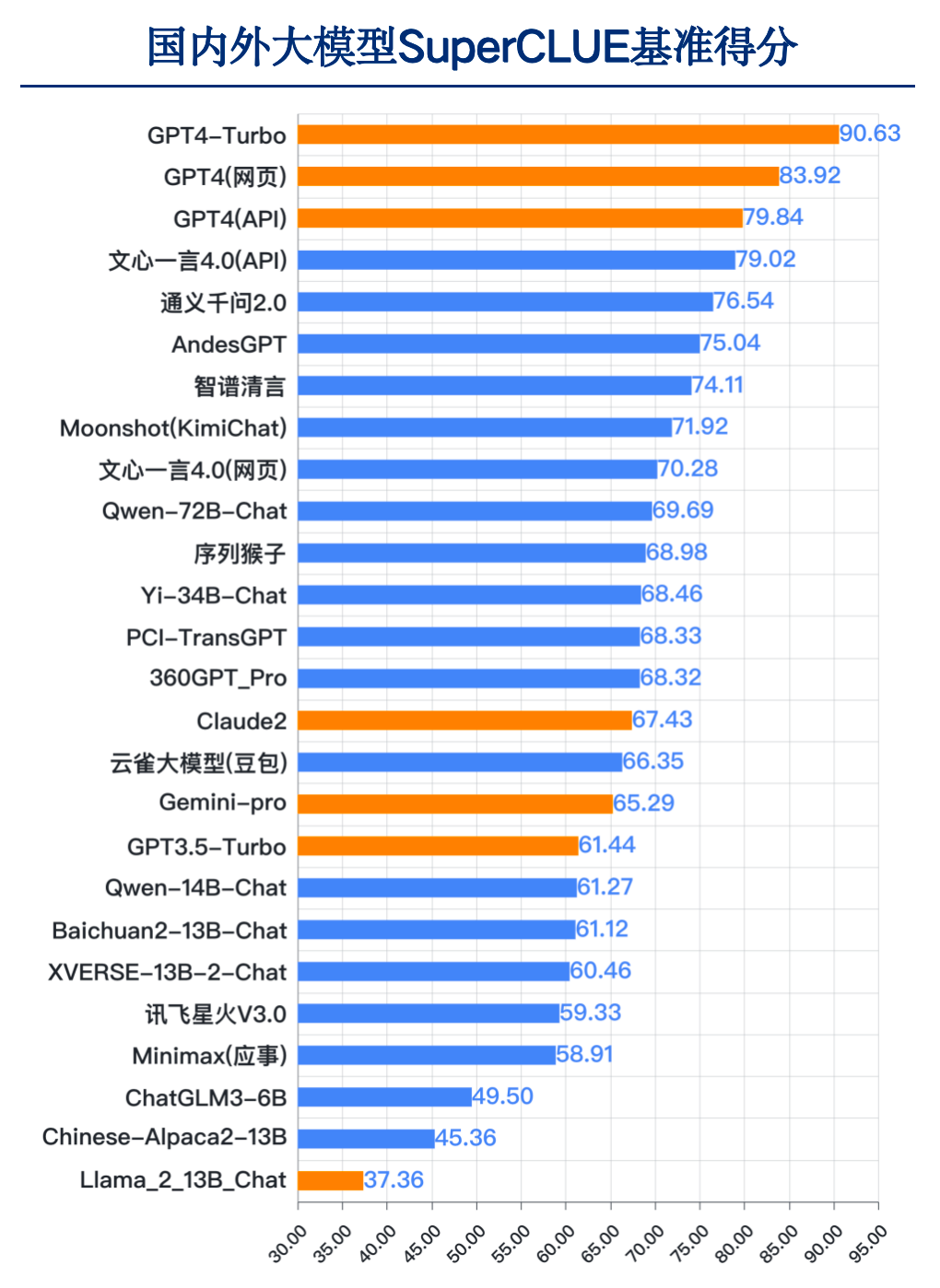
来源:SuperCLUE, 2023年12月28日
国内外差距依然明显。GPT4-Turbo总分90.63分遥遥领先,高于其他国内大模型及国外大模型。其中国内最好模型文心一言4.0(API)总分79.02分,距离GPT4-Turbo有11.61分,距离GPT4(网页)有4.9分的差距。
必须看到的是,过去1年国内大模型已经有了长足的进步。综合能力超过GPT3.5和Gemini-Pro的模型有11个,比如百度的文心一言4.0、阿里云的通义千问2.0和Qwen-72B-Chat、OPPO的AndesGPT、清华&智谱AI的智谱清言、字节跳动的云雀大模型等都有比较好的表现。
另外国内开源模型在中文上表现要好于国外开源模型,如百川智能的Baichuan2-13B-Chat、阿里云的Qwen-72B、Yi-34B-Chat均优于Llama2-13B-Chat。
国外模型平均成绩 VS 国内模型平均成绩
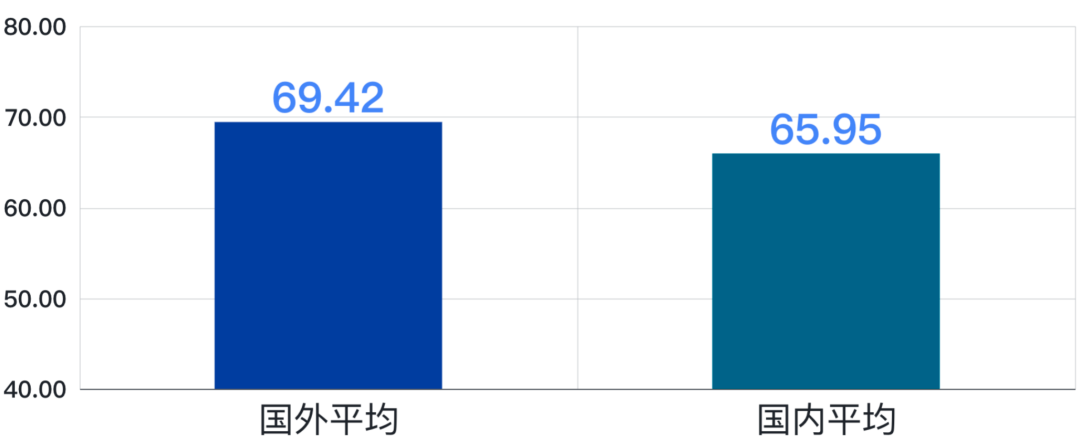
在SuperCLUE测评中,国外模型的平均成绩为69.42分,国内模型平均成绩为65.95分,差距在4分左右。可以看出,国内外的平均水平差距在缩小,11月差距在10分左右。04国内大模型竞争格局
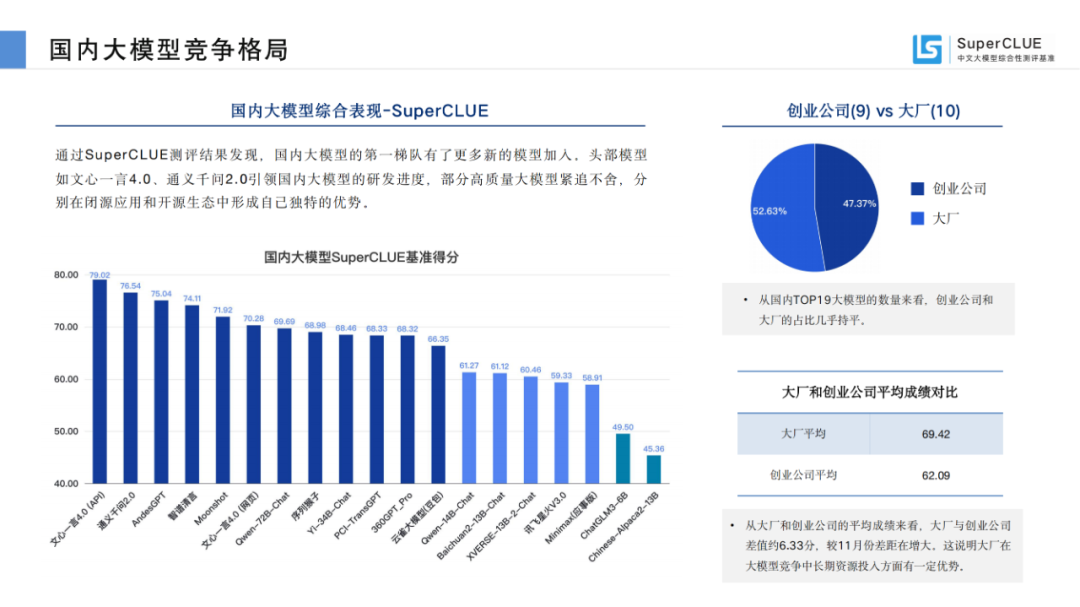
通过SuperCLUE测评结果发现,国内大模型的第一梯队有了更多新的模型加入。头部模型如文心一言4.0、通义千问2.0引领国内大模型的研发进度,部分高质量大模型紧追不舍,分别在闭源应用和开源生态中形成自己独特的优势。
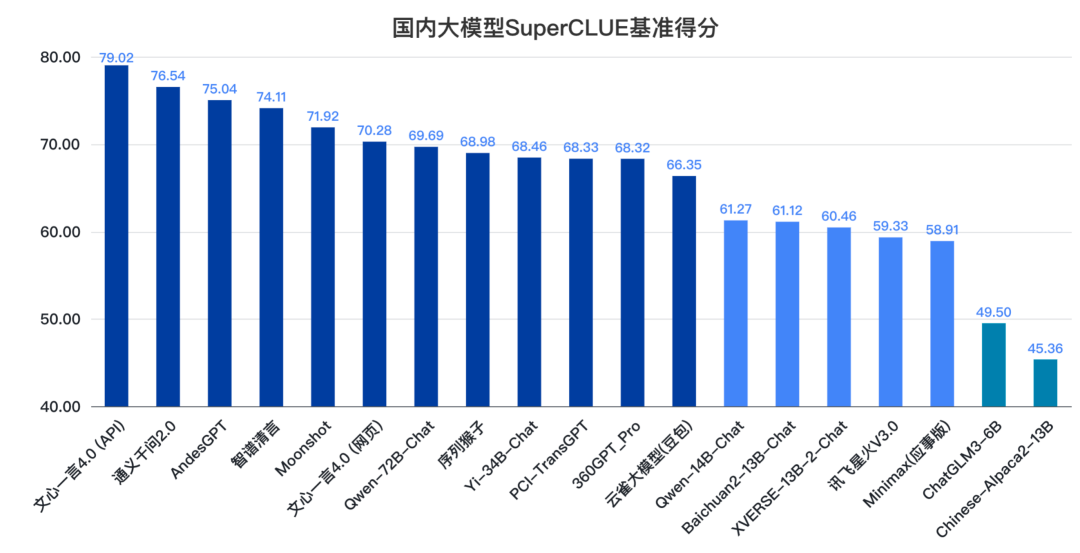
来源:SuperCLUE, 2023年12月28日
从国内TOP19大模型的数量来看,创业公司有9个, 芯片采购平台大厂有10个,占比几乎持平。
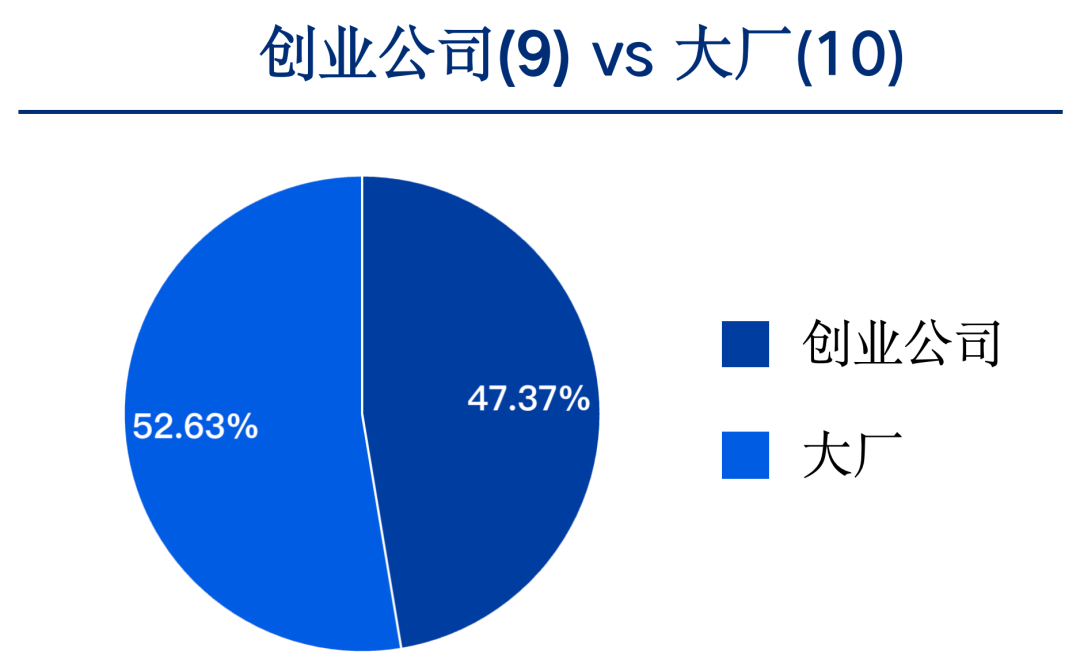
从大厂和创业公司的平均成绩来看,大厂研发的大模型平均成绩为69.42分,创业公司研发的大模型平均成绩为62.09分,差值约6.33分,较11月份差距在略有增大。这说明大厂在大模型竞争中长期资源投入方面有一定优势。

05国内大模型历月前三甲
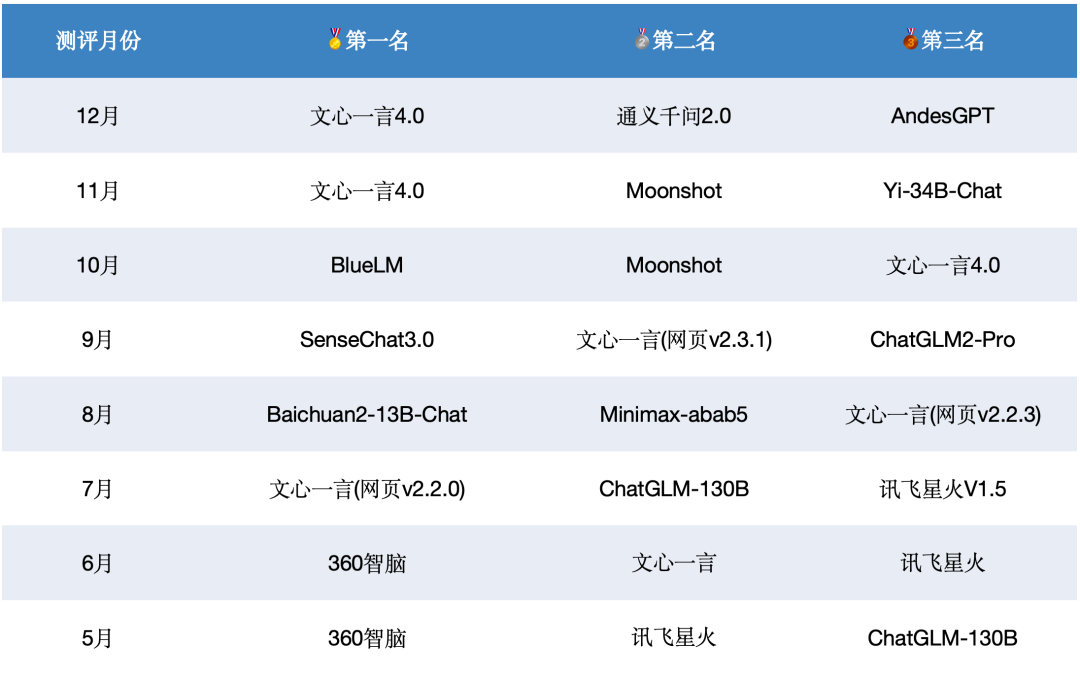
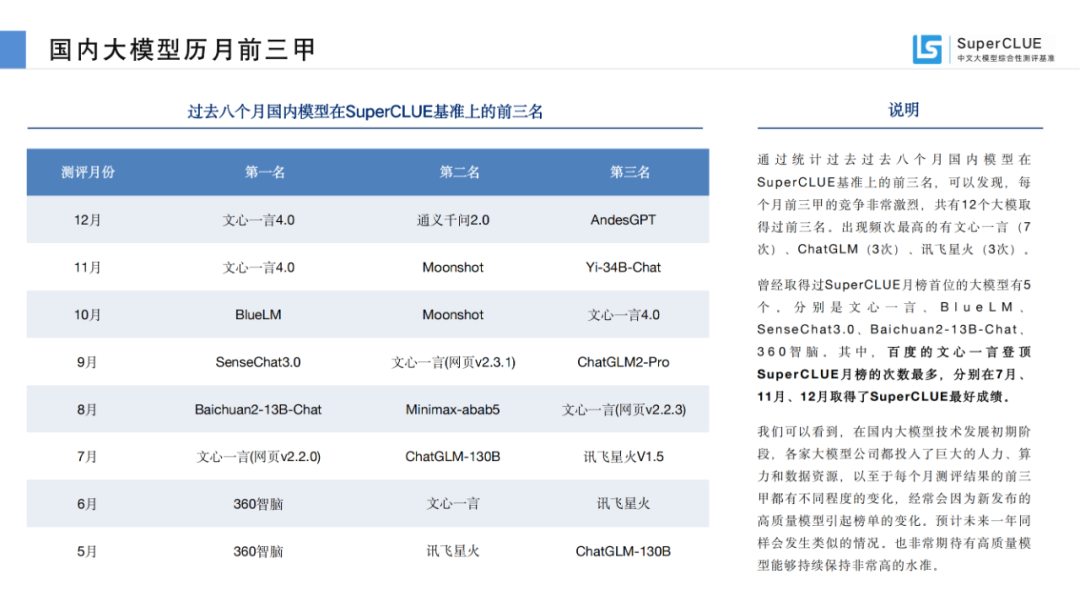
过去八个月国内模型在SuperCLUE基准上的前三名。
来源:SuperCLUE
曾经取得过SuperCLUE月榜首位的大模型有6个。分别是文心一言、BlueLM、SenseChat3.0、Baichuan2-13B-Chat、360智脑。其中,百度的文心一言登顶SuperCLUE月榜的次数最多,分别在7月、11月、12月取得了SuperCLUE最好成绩。
我们可以看到,在国内大模型技术发展初期阶段,各家大模型公司都投入了巨大的人力、算力和数据资源,以至于每个月测评结果的前三甲都不同程度的变化,经常会因为新发布的高质量模型引起榜单的变化。预计未来一年同样会发生类似的情况。也非常期待有高质量模型能够持续保持非常高的水准。
06大模型对战胜率分布图
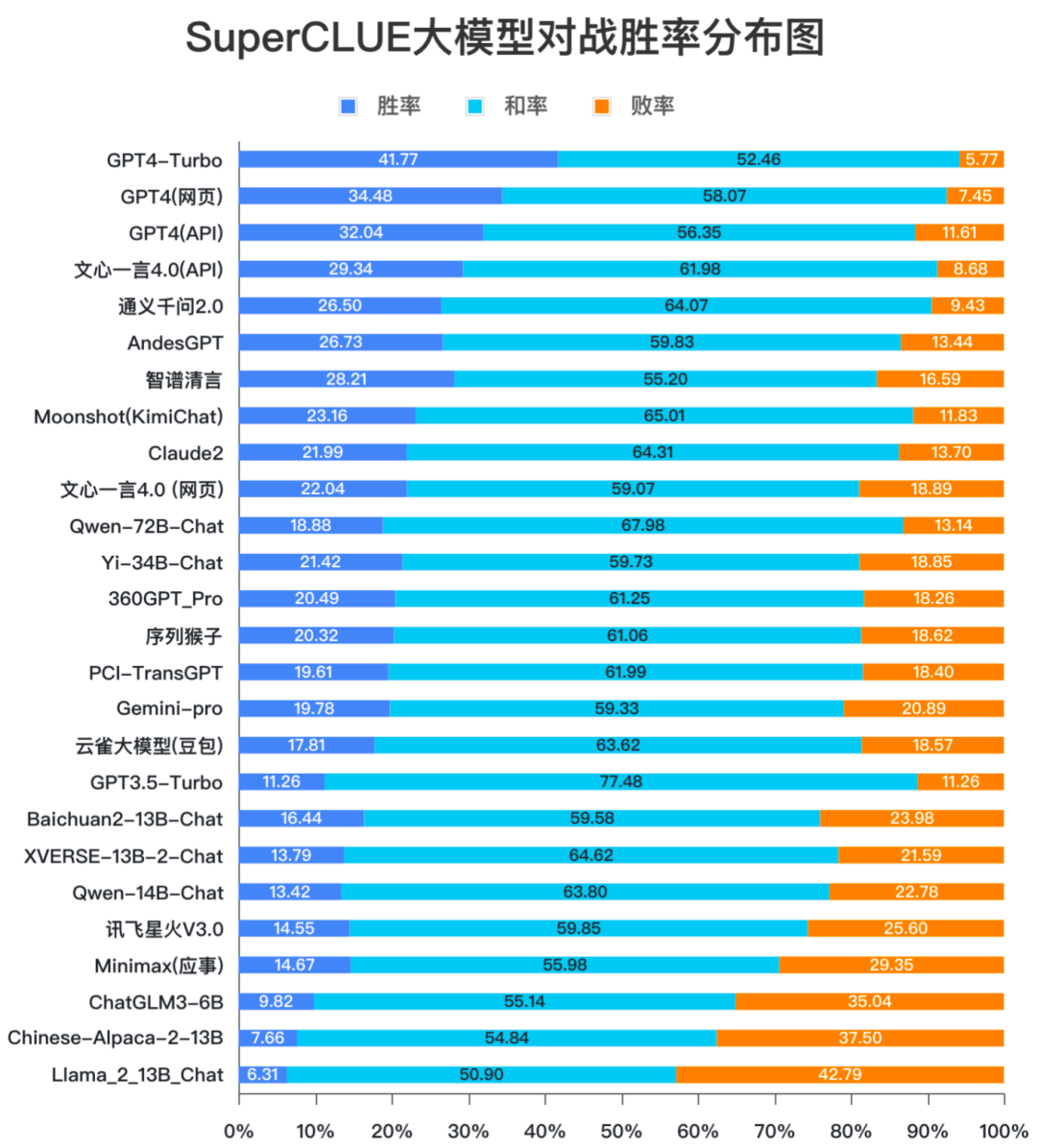
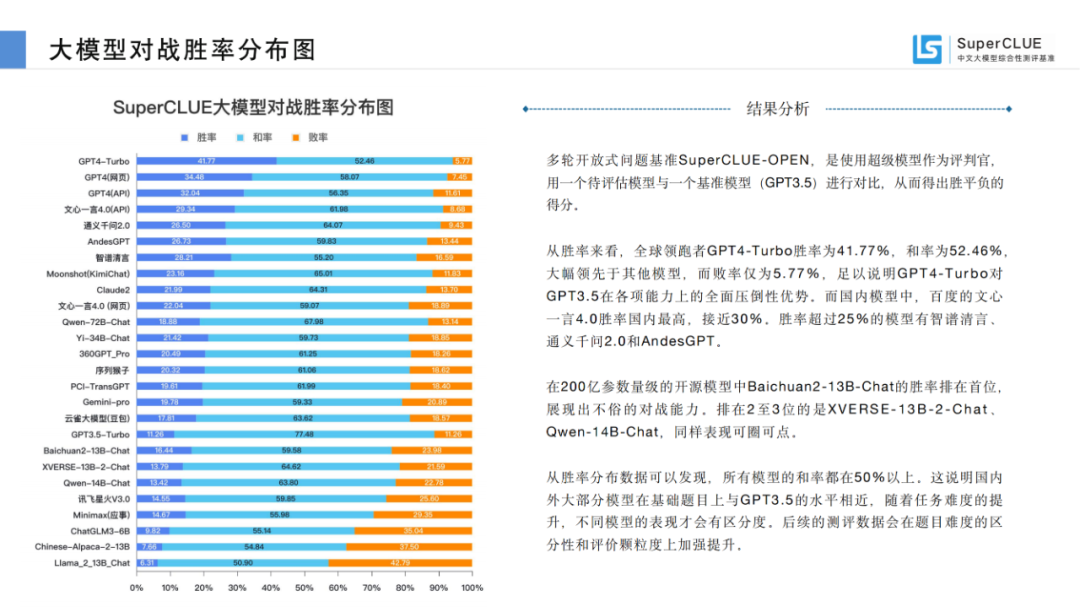
从胜率来看,全球领跑者GPT4-Turbo胜率为41.77%,和率为52.46%,大幅领先于其他模型,而败率仅为5.77%,足以说明GPT4-Turbo对GPT3.5在各项能力上的全面压倒性优势。而国内模型中,百度的文心一言4.0胜率国内最高,接近30%。胜率超过25%的模型有智谱清言、通义千问2.0和AndesGPT。
来源:SuperCLUE, 2023年12月28日
在200亿参数量级的开源模型中Baichuan2-13B-Chat的胜率排在首位,展现出不俗的对战能力。排在2至3位的是XVERSE-13B-2-Chat、Qwen-14B-Chat,同样表现可圈可点。
从胜率分布数据可以发现,所有模型的和率都在50%以上。这说明国内外大部分模型在基础题目上与GPT3.5的水平相近,随着任务难度的提升,不同模型的表现才会有区分度。后续的测评数据会在题目难度的区分性和评价颗粒度上加强提升。
07主观与客观对比
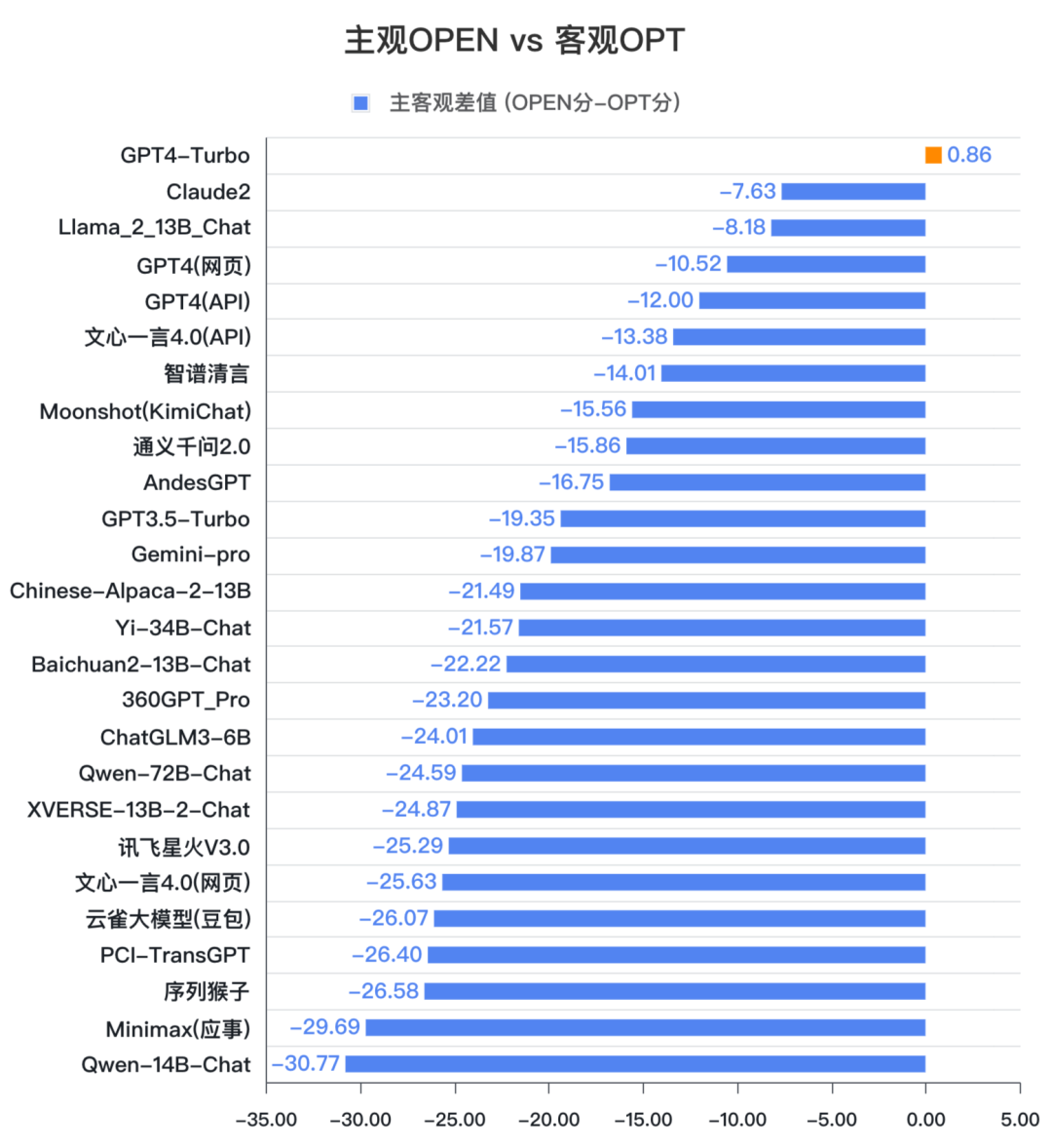
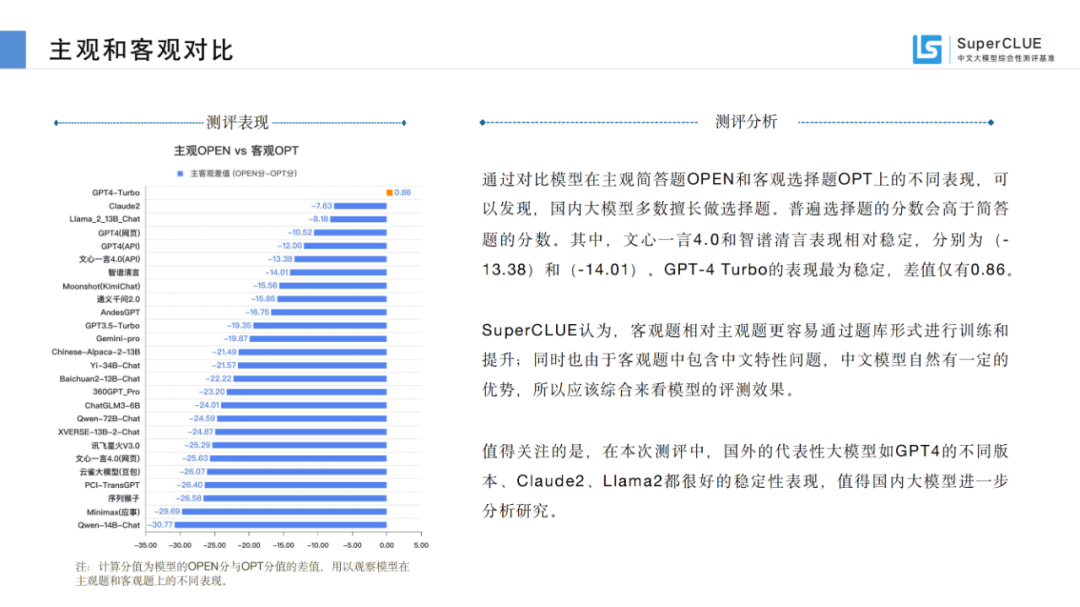
通过对比模型在主观简答题OPEN和客观选择题OPT上的不同表现,可以发现,国内大模型多数擅长做选择题。普遍选择题的分数会高于简答题的分数。
注:计算分值为模型的OPEN分与OPT分值的差值,用以观察模型在主观题和客观题上的不同表现。数据来源:SuperCLUE, 2023年12月28日
其中,文心一言4.0和智谱清言表现相对稳定,分别为(-13.38)和(-14.01)。GPT-4 Turbo的表现最为稳定,差值仅有0.86。
SuperCLUE认为,客观题相对主观题更容易通过题库形式进行训练和提升;同时也由于客观题中包含中文特性问题,中文模型自然有一定的优势,所以应该综合来看模型的评测效果。
值得关注的是,在本次测评中,国外的代表性大模型如GPT4的不同版本、Claude2、Llama2都很好的稳定性表现,值得国内大模型进一步分析研究。
08开源竞争格局
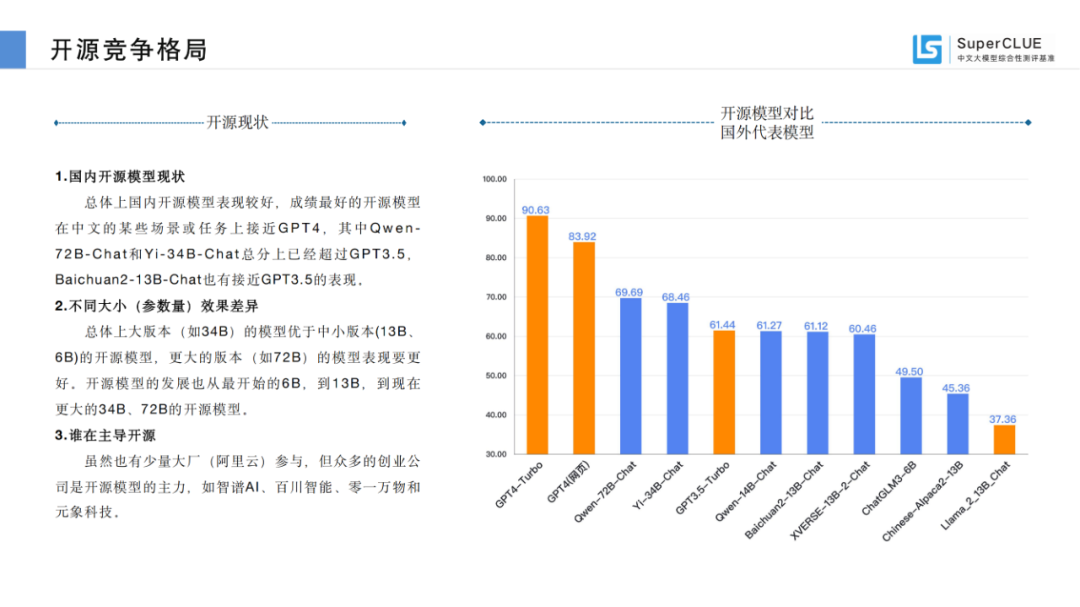
总体上国内开源模型表现较好,成绩最好的开源模型在中文的某些场景或任务上接近GPT4,其中Qwen-72B-Chat和Yi-34B-Chat总分上已经超过GPT3.5,Baichuan2-13B-Chat也有接近GPT3.5的表现。
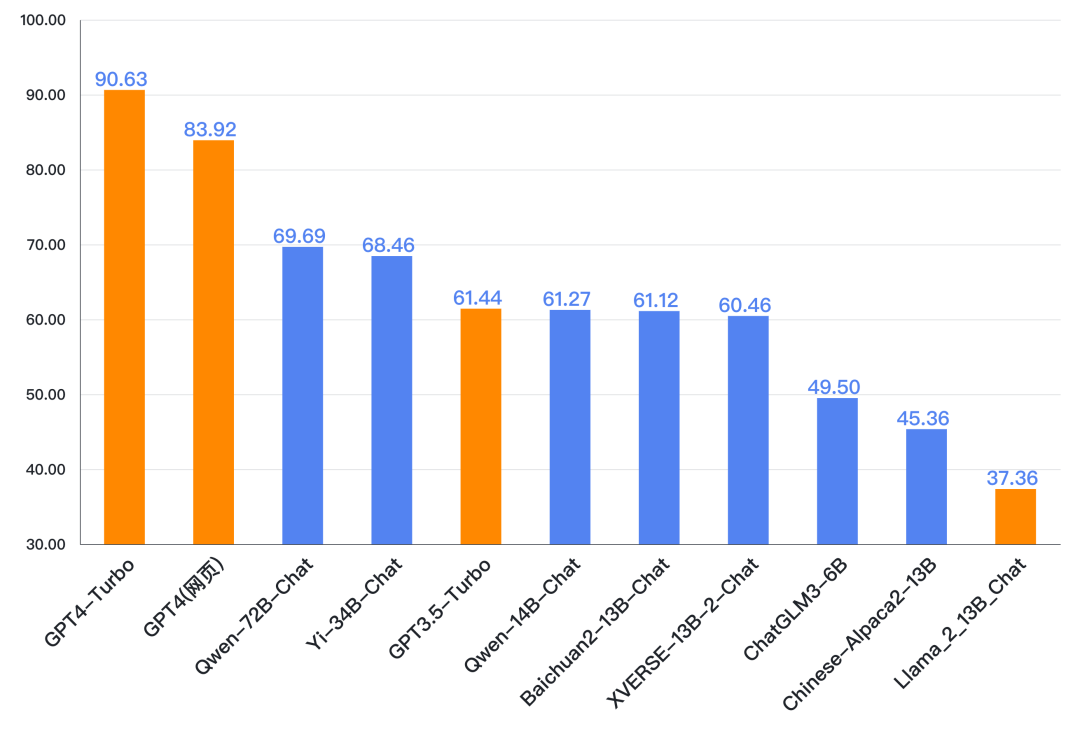
来源:SuperCLUE, 2023年12月28日
总体上大版本(如34B)的模型优于中小版本(13B、6B)的开源模型,更大的版本(如72B)的模型表现要更好。开源模型的发展也从最开始的6B,到13B,到现在更大的34B、72B的开源模型。
虽然也有少量大厂(阿里云)参与,但众多的创业公司是开源模型的主力,如智谱AI、百川智能、零一万物和元象科技。
具体内容如下































- 亿配芯城接入DEEPSEEK AI 大模型,让芯片采购更灵活2025-04-25